
February 2, 2018
As we go further in this direction, many new use cases for augmenting the vehicle experience become possible and should be explored. One of the projects we’re building for our client, requires a way for collecting and processing info about car surroundings: identifying other cars in near vicinity, street signs, people, architectural landmarks and infrastructure elements.
Understandably, there was no platform providing this which we could easily adapt for our needs. We wanted to dive deep into this topic for a long time so we eagerly jumped on this opportunity and started building our own solution!
We knew from the get-go that we wanted the system to be generic and fully based on neural networks and deep learning, since it worked very well for us in other projects. That said, we needed a tangible, concrete use case for validating results in the real life. We decided to go with a popular problem: detecting cars and license plates.
License plate detection is a common use case which has been solved (somewhat) several times, but felt that we could provide something better than the current options.
Detection Approach
One of our first decisions was to use a high-quality 4K, rear-mounted camera with wide-angle lens. Thanks to the wide angle, we’re able to capture a wide context of the surrounding area. High resolution gave us the opportunity for extracting a lot of detail even for objects which are relatively far away.
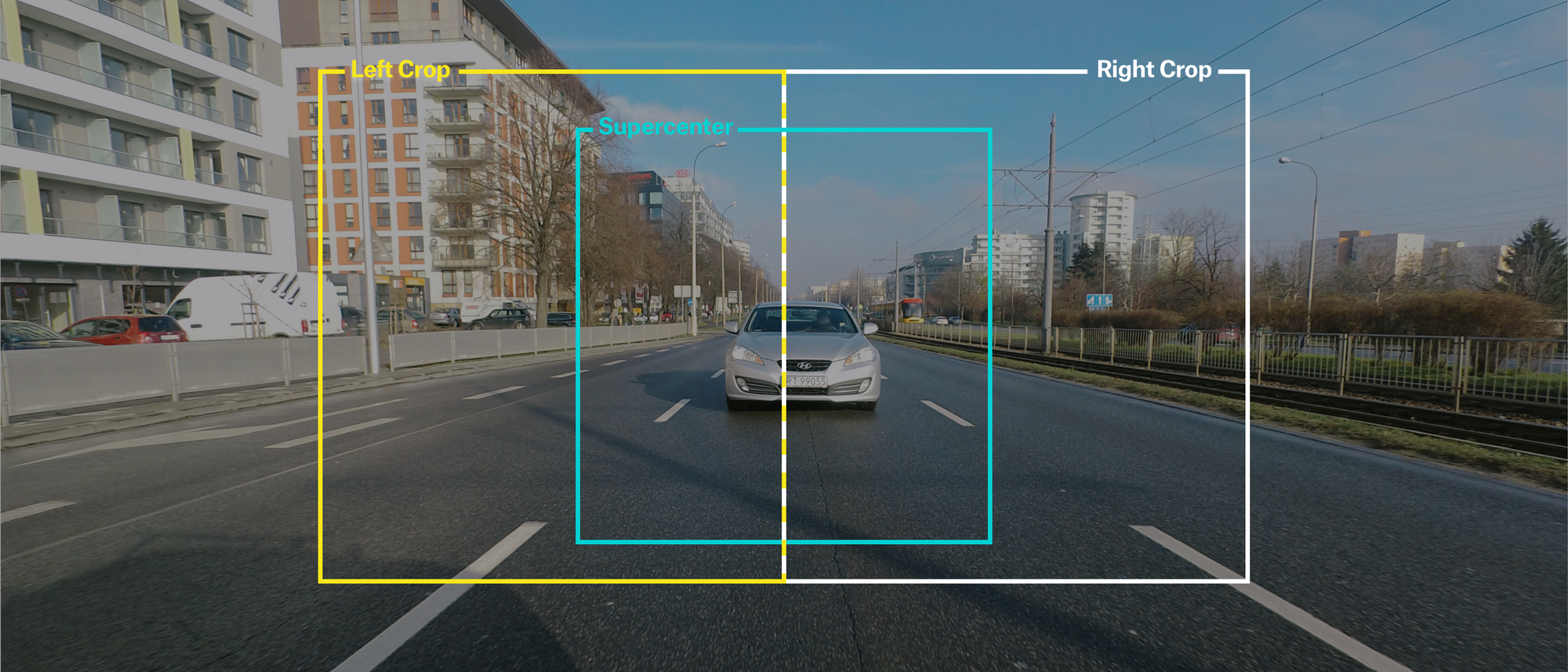
After some experimentation we decided to subdivide the image into 3 distinct regions as the first step of the algorithm. This is important as we wanted to cut-away large areas of “sky” and non-relevant empty content. Additionally, processing smaller images in parallel is way more efficient than processing one big high-resolution image. Lastly, processing full 4K input was a bit too much for the hardware.
We identified that a lot of really interesting action is happening right behind the car, in the “supercenter”. This is the picture region where detection is most important for us, so we made it more prominent, overlapping left/right crops with a higher zoom factor.
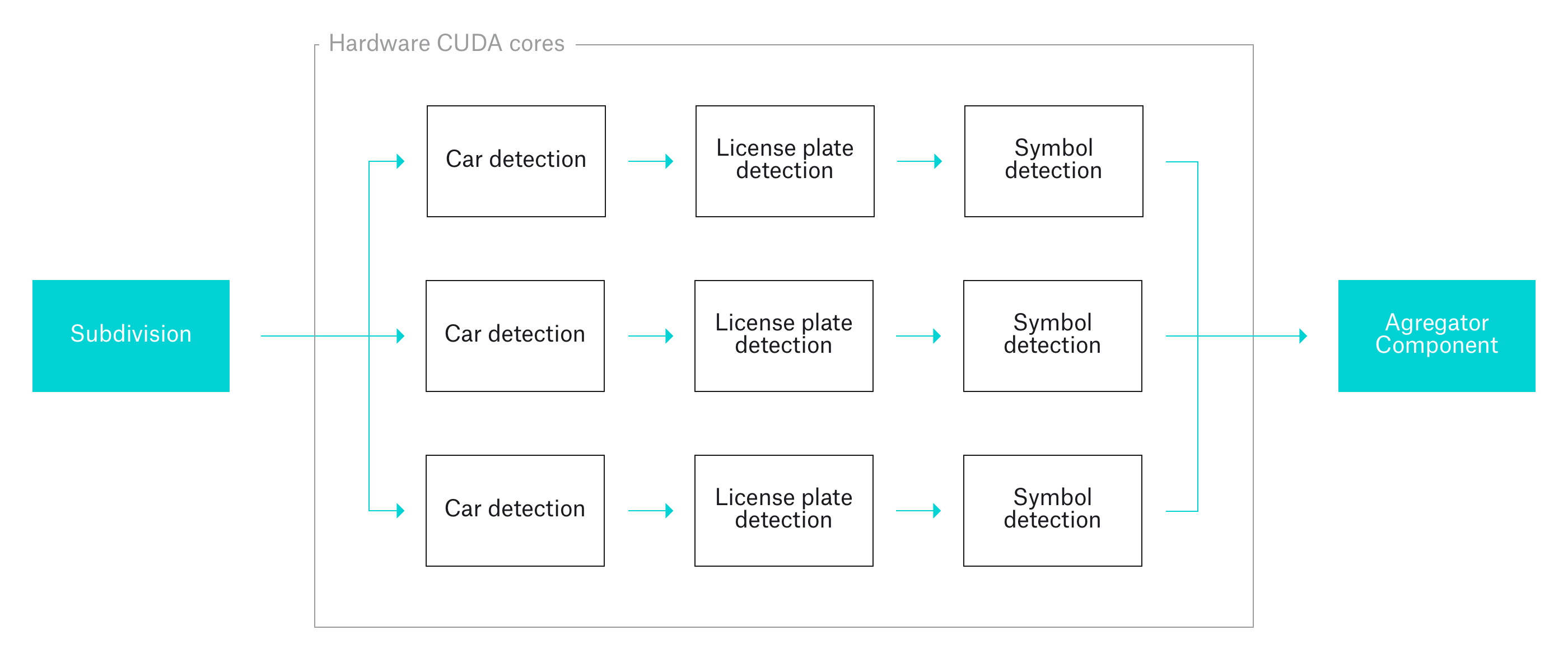
For the detection itself we decided to use a 3-step approach using 3 individually trained DNN networks. First we detect and isolate the car itself. Then, we cut out the license plate and finally we pass the symbols through a network picking individual letters and numbers.
Lastly, detection data from all 3 images is aggregated/joined together eliminating possible duplicates.
For each step we used a custom-trained net:
- Cars — 90 000 iterations
- Plates — 102 000 iterations
- Numbers/letters — 97 000 iterations
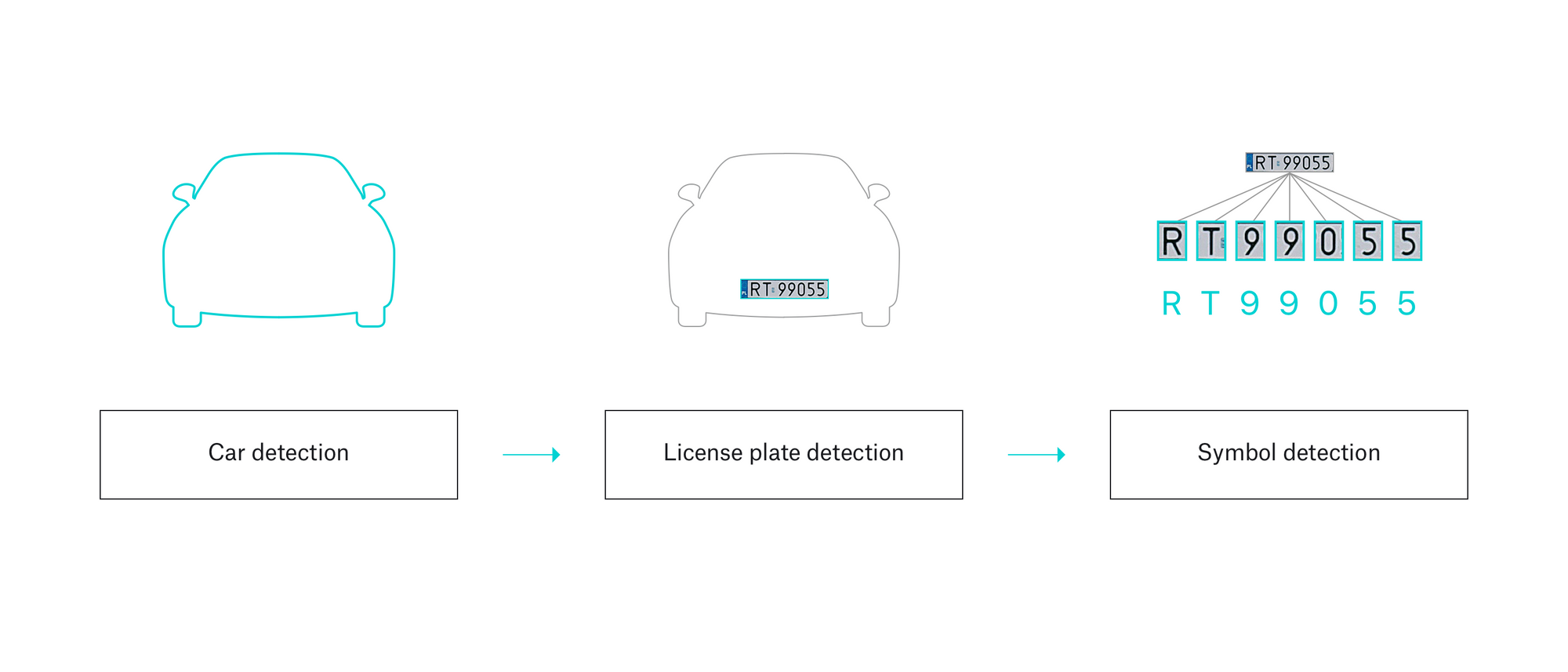
To prepare the networks, we drove around the city a lot and captured actual footage to feed the training system… after a meticulous process of describing and marking-it-up by our QA team.
Later, while doing actual testing of the solution, we were always recording everything and re-feeding the data again into the system to improve the net (in the beginning we pre-trained the model using public-available car auction)
As for the detection itself, we used a state of the art convolutional neural network with bounding box regression and classification. This popular approach avoids the pitfalls of traditional approach with repurposing classifiers to perform detection which is extremely slow and cannot easily scale to modern GPU accelerated hardware. The method has been described in papers and has a tangible implementation effort.
Why not OpenALPR?
OpenALPR is a popular open-source library for extracting license plate numbers from images. Since there are some very enthusiastic articles about its accuracy, it’s only natural to ask why we decided to devise our own Deep Learning solution instead of reusing a readily available component.
There are several reasons for that:
- Generic approach: As mentioned earlier, license plates were just a test-case and were not interesting for us per se. What we really wanted was to build a system for quickly detecting, identifying, categorising and reacting to different elements visible on the road, including, but not limited to license plates. That’s why we needed a deeper, more far-reaching solution.
- Hardware acceleration: We wanted the solution to be fast and we wanted it to scale in future with the technological advancements in the area that we’re expecting. As we’re running our automotive software on Nvidia platforms, that meant we wanted to have support for 256 parallel computing CUDA cores that the hardware provides. While OpenALPR has a certain level of GPU support through underlying OpenCV, it’s only partial due to LBP mechanism… and we weren’t able to get it working on our platform anyways.
- Quality of detection: OpenALPR and all similar solutions are optimised to work with a very specific, constrained data set in ideal lighting/visual conditions. License plates vary across countries and so does OpenALPR detection quality. It seems to work well with US plates, somewhat acceptable with European plates and downward tragically with Singapore plates, and this is just looking at the ones we tested. In contrast our Deep Learning-based solution was able to detect Singapore plates with just a bit of extra training data.
In general, the license plate image needs to be somewhat ideal for the detection to work acceptably in OpenALPR — high contrast, dark text on a white background, not much skew/rotation, acceptable resolution.
In particular the resolution requirement means detection range is very limited (notice: at 4k resolution + wide lens, the image of the plate at 10 meters is less than 100px wide and inaccessible for alpr detection).
Results & Comparison

The high-res license plate on the left can be processed by OpenALPR and our solution equally well giving correct prediction. However, the lower-res, far-distance image on the right fails on OpenALPR but can be detected by our DNN solution without problems.
Additionally our solution can deals better with processing multiple plates from single image, ex:

OpenALPR is able to handle only two license plates (middle and right), while our solution processes all three.
Notice that both images can be processed by a human without issue. It’s a certain scheme: often we would look at an image that’s perfectly readable by a human, but it simply doesn’t fit a certain technical condition on OpenALPR side. In contrast, DNN based solutions tend to approach a level of success similar to that of a human (“if a person can read it, the network will too”).
In summary, in our experience there is at least a magnitude of difference between OpenALPR (and similar) solutions vs. DNN based approach in practical testing. The difference is visible across all parameters: detection rate, consistency and the physical range required for the detection to work at all.
Next Steps
Implementing the license plate recognition use case was an interesting challenge with surprising benefits. We learned there are a lot of commercial use-cases for a high-quality, high-range license plate/car detection and identification through Machine Learning.
What’s more, we also validated our platform approach for generic object detection and created fundamental building blocks for more advanced things to come.
Having all this in place, we’re looking forward to streamline everything we learned in other ML/AI projects and provide a complete, high-efficient and easily accessible platform for next-generation context-aware automotive driving solution.
See you then!
This post was written by Michał Dominik Kostrzewa, Head Of Special Projects. In need of some brain power? Reach out to us via hello@ynd.co with your questions about ML/AI projects.